壹 前言
2017年AI 掀起第一波浪潮,以深度學習技術所建構的AI應用開始進入日常生活,由商品推薦、語音助理、人臉辨識到科技執法,同年Google提出強大的Transformer AI模型,促進可用來執行多種任務的基礎模型研究蓬勃發展,並帶動生成式AI應用興起;2022年第二波AI浪潮興起,Midjourney 以文字生成繪畫的AI工具展現驚人的繪畫能力,其作品於8月贏得美國美術展的首獎,ChatGPT AI聊天機器人於11月問世後更引起全球對AI能力大幅進展的關注。依據Mckinsey推估,生成式AI帶動的自動化技術將加速勞動力轉型,最快在2030年,當今人類一半的工作活動會由AI取代 [1],這代表許多經濟活動將建構在AI之上。

AI能夠幫助提升教育與醫療品質、改善環境問題,然而未妥善管理則會對個人、組織、及全球生態系產生負面傷害 (圖一),例如對特定族群有偏見而傷害基本人權、散布假消息影響組織名譽、傷害全球金融系統運作等等。為了避免AI傷害,以人為本的負責任AI是全球關注的議題,圖二顯示近年相關的研究數量大幅成長- 2023年篇數較2018年成長50倍;市場分析公司CB insight篩選了2023年100間著名的AI新創 [2] ,其中即包含好幾間獲得高額資金投資的新創聚焦於發展負責任AI,例如 Anthropic 提出constitutional AI - 使用經典法規訓練模型,讓模型學習產生安全、有用、無害的回覆,Cohere 構建的語言模型旨在最小化有害輸出。
負責任AI是一套促進 AI 以人為本的方法,讓AI開發者在其研發及系統運作流程中加入透明、公平、可解釋、當責、自治、可持續性、可信任等價值,避免AI產生傷害,並且在符合法規及倫理的範圍中發揮正面效益。本篇文章介紹實作負責任AI需要關注的三個面向 - 了解法規、規劃AI治理架構、及使用AI風險檢驗工具;接續的章節將各以一個實例分析負責任AI在這三個面向的發展現況,分別是歐盟「AI Act 」法案、美國NIST提出的「AI RMF (Risk Management Framework) 」 風險管理框架指引,以及美國MIT及Harvard 學術研究機構提出的「Dataset Nutrition Label (DNL)」數據集營養成分標籤工具。
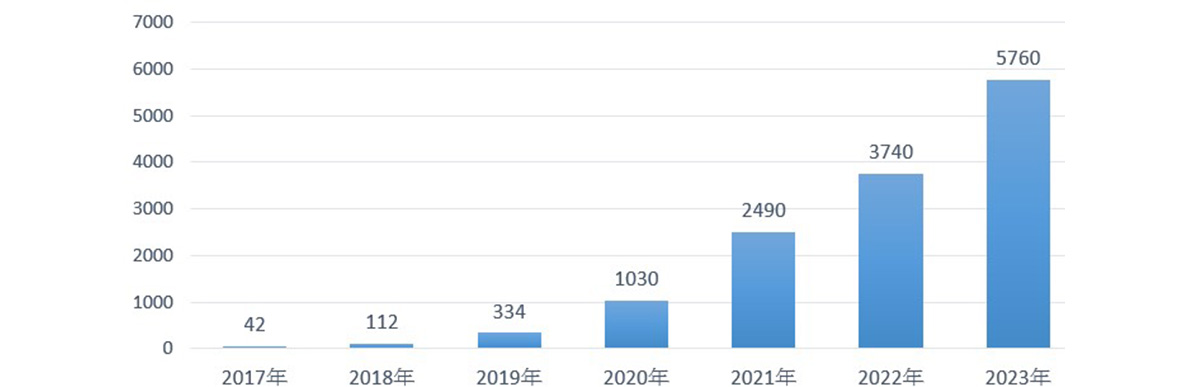
(由Google學術搜尋網站統計,2023年數量使用當年1到8月發表的篇數推算)
貳 科技發展現況
一、 AI法規:歐盟AI Act
歐盟AI Act是全球發展最快速的AI法案。2021年由歐盟理事會 (European Commission)提出,2023年6月通過歐洲議會 (EU Parliament) 審查,交由歐洲高峰會 (European Council)審查,預計1至2年內正式上路,由歐洲理事預計成立AI委員會及專家團體監督法規的執行,確保AI系統是安全的才會推到市場上。這項法規除了可能對歐洲AI開發和使用產生重大影響, 預期也將為AI監管制定全球標準,成為對其他國家製定自己AI法規時的參考。

AI Act的目標是要確保在歐盟地區AI技術能永續、可信任的為人服務,並促進AI研發及創新應用發展。它的基本精神是基於風險等級進行管理,並要求AI系統揭露適當資訊。此法規將AI的風險分為四類 [3],第一類具不可接受的風險 (unacceptable risk) - 違反歐盟社會價值及造成傷害的AI應用被禁止使用,例如政府對人民進行社會信用評分、運用AI技術延長卡車司機駕駛時間等應用;第二類為高風險 (high risk),此類AI系統商需要確保其設計、發展、品質管理符合法規,並依AI Act規範揭露系統資訊,通過合格評定後才可上市;第三類是有限風險 (limited risk),要求於提供服務時告知使用者正在和AI互動,例如聊天機器人、深偽影片、生物特徵分類等;第四類為最小風險 (minimal risk),不需要特別監管。


AI Act要求被列為高風險的AI系統商提供清楚、簡捷、容易取得的指引文件給使用者使用,以及完整的技術文件給監管當局審查。歐盟理事會研究人員於2023年發表了一篇學術論文 [4],詳細整理AI Act 規範評定為「高風險」系統需提出的技術文件,並且挑選幾個知名的「AI文件化工具」,針對AI Act要求的資訊元件逐一評估可達到的程度,目的是要了解技術演進的情況,以及作AI文件化方案潛在的標準規格的基礎。表一、表二分別列出此份研究整理的AI Act對數據集及AI系統要求的部分資訊元素,分為針對監管當局 (A, authority)、及使用者 (U, user) 等兩組受眾;表三則列出四組「AI文件化工具」的涵蓋度分析結果。本文在子章節4 將介紹其中的 Dataset Nutrition Label 工具。

二、 實作框架:美國NIST AI RMF
美國國家標準與技術研究院 NIST (National Institution of Standards and Technology) 於2023年發布AI RMF (Risk Management Framework) 風險管理框架,為開發、部署、及使用AI系統的組織提供建構負責任AI的技術指引,並鼓勵自發性採用,於AI系統的生命週期中持續並即時管理AI技術可能產生的諸多風險。[2]
AI RMF將風險管理活動分為4項高階功能,並於其下展開多個分類及子分類,以及描述具體的行動及產出。以下介紹這4項高階功能的基本作用:
- 治理 (Govern) 功能,於企業組織中建立管理 AI風險的文化、架構、治理政策與程序,並結合其他三組功能,確保法規、道德、社會層面的風險能被有效辨識及管理。
- 對照 (Map) 功能,針對組織所研發及使用的AI系統,辨識其相關背景資訊,例如預期用途、潛在用戶、需要依循的法規等,並且指出在資料、模型、部署環境中可能存在的風險,作為進行AI設計、開發、部署的考量因素。
- 量測 (Measure) 功能,評估 Map 功能所指出的風險的影響程度,並且監測 AI系統的表現、及衡量風險管控機制是否有效。
- 管理 (Manage) 功能,降低或消除找到的風險,實作風險管控機制、定期檢視以確保有效,並採取適當行動來排除這些風險。

三、 數據集文件化工具:Data Nutrition Label
數據是AI的重要基礎,模型所使用的訓練數據集品質直接影響模型的輸出;如同人的判斷會被其所見所聞影響,數據集如果有問題或資料有缺失,所訓練的模型也很可能產生有問題的結果。

DNP (Data Nutrition Project) 組織發現多數的AI開發團隊會在完成模型開發後才開始檢驗推論的合理性,如果有偏頗的情況,才又回頭檢查存在於數據集的問題 (見圖五的反饋迴路),但這樣的做法耗時、效率低,更重要的是可能未能真正解決問題。因此,DNP 提出在選用數據集的階段即開始進行數據集盤查步驟 (dataset interrogation),並且引用大眾熟悉的「Nutrition Label - 食品成分商標」概念,設計了一套標準的數據集成分標籤 (Dataset Nutrition Label, DNL),將質化及量化的品質衡量資料打包為一組標準格式的標籤,幫助數據集揭露關鍵資訊,幫助盤查數據集工作的進行,達到降低AI推論風險的目的 [5][6]。

數據集成分標籤 (DNL) 由多個資料模組構成,目前的第三代版本包含基本描述、如何使用、數據集的相關資訊、及推論風險等四部分 (圖六)。DNP官網提供了幾組可預覽的數據集標籤範例 [7],其中有一組是知名的文轉圖 AI 服務 Stable Diffusion 所使用的圖片數據集LAION-5B。 LAION-5B 是一個大型的公開圖文對照數據集,包含2008年到2022年於internet收集的50 億張圖片及描述文字。這份 LAION-5B 標籤尚不是最終版本,但可以看到一些已分析到的議題,包含:
- 內容源自2008至2022年間發布的網絡圖像,可能會反映存在於早年網絡內容的偏見。
- 內容以歐美網路圖片為主,導致基於此數據的推論偏重歐美文化及社會觀點。
- 網路內容中長期存在的刻板印象可能影響與人相關的推論結果。
- 可能存在具冒犯性的敏感內容。
這些議題恰巧與彭博社 (Bloomberg) 於2023年公開的一項測試相呼應。這篇名為「Human are biased, Generative AI is even worse 人類有偏見,生成式AI更糟」的文章描述了一份使用Stable Diffusion生成14種行業的工作者,及和3種犯罪類型相關人臉的測試結果,顯示 Stable Diffusion放大了原本社會上存在對種族及性別的成見。此實驗約產生 5千張圖片,高薪工作者大部分是膚色較淺的男性,例如醫生、法官、CEO,低薪工作者則多數是女性及深膚色的男性,例如管家、收銀員、警衛,而3種犯罪類型則以深膚色及中東國家男性居多 [8]。
參 結論
當AI逐漸取代、或是輔助有高度影響力的人類工作,如執法、醫療、教育等等,就如同人類進入職場,除了要具備專業領域的知識,必須能遵循倫理道德及法規規範,而在作法上,也就是要落實本文介紹的負責任AI。
除了歐盟的AI Act,包含美國、日本等許多國家都在積極擬定AI法規,台灣的AI基本法預計2023年9月提出,預期會讓國內AI技術與應用生態發展更為健全,並且接軌國際的發展。由於AI具有規則不透明、複雜、機率導向、推論結果與訓練資料密切相關等特性,這些法規規範的共通要求都是將AI系統透明化,也就是由black box轉為glass box,讓監管機構可以檢驗、讓使用者知道如何正確使用。是時候在機構內部建立實作負責任AI的最佳案例,謹慎評估每一項AI服務適用的範圍、是否符合法規及倫理,釋放AI對企業及個人的良善價值,以及運用AI創造更包容、更平等的世界。
肆 參考文獻
[1] Mckinsey, “The economic potential of generative AI: The next productivity frontier”, 2023.6.14
[2] Tabassi, Elham. "Artificial Intelligence Risk Management Framework (AI RMF 1.0).", 2023
[3] Madiega, Tambiama André. "Artificial intelligence act." European Parliament: European Parliamentary Research Service (2021).
[4] I. Hupont, M. Micheli, B. Delipetrev, E. Gómez and J. S. Garrido, "Documenting High-Risk AI: A European Regulatory Perspective," in Computer, vol. 56, no. 5, pp. 18-27, May 2023, doi: 10.1109/MC.2023.3235712.
[5] Holland, Sarah, et al. "The dataset nutrition label." Data Protection and Privacy 12.12 (2020): 1.
[6] Chmielinski, Kasia S., et al. "The dataset nutrition label (2nd Gen): Leveraging context to mitigate harms in artificial intelligence." arXiv preprint arXiv:2201.03954 (2022).
[7] The Dataset Nutrition Label, ‘https://labelmaker.datanutrition.org/#label-list'
[8] Bloomberg, " Humans are biased. Generative AI is worse", 2023.6.12.