壹 前言
語言學習的目標通常包括聽、說、讀、寫四個方面,其中口說能力更是一個直接影響人與人之間是否能有效溝通的重要因素。傳統的口說教學是由老師帶領學生進行發音及對話等練習,這會耗費老師大量時間和精力來反覆指正學生錯誤,學生也需持續付出學習成本。隨著電腦科學及人工智慧的進步,AI語音評分方法被設計提出並演進,已經能夠即時提供媲美人類專家反饋和個人化學習體驗,學生能夠在任何時間和地點學習,並且能夠根據個人進度和需求調整課程。評分技術可以幫助學生練習發音、提高聽力技能及增強口語表達能力,在語言學習領域中有著廣泛的應用前景。接下來,我們將說明語音評分的技術發展及應用。
貳 科技發展現況
一、 語音評分技術簡介
「語音評分」(Speech Assessment)或更準確地稱為「發音評分」(Pronunciation Assessment),又或稱「電腦輔助發音訓練」(Computer-Assisted Pronunciation Training, CAPT),是一種以語音辨識為基礎的技術,其首要任務為錯誤發音檢測與診斷(Mispronunciation Detection and Diagnosis, MDD),即是藉由語音辨識的聲學模型將正確及錯誤的發音區分出來。傳統主流的方法為Goodness of Pronunciation (GOP) [1]及其延伸方法,首先使用Viterbi演算法進行文本和語句的強制對齊,以取得文本提示中每一個音素(語音中最小的單位)和其相對應的語音特徵序列段落,然後利用此對應資訊計算其分數。最新研究也有結合Connectionist Temporal Classification (CTC) 和Attention Model的端到端語音辨識(結合語音特徵擷取模組、聲學模型、語言模型、解碼模組為一體)模組來發展的端到端錯誤發音偵測與診斷模型[2],能夠回饋更細緻的診斷結果。
一般而言,語音評分系統會採用音素進行評估,以英語來說有44個音素,包括20個母音和24個子音。例如,當學習者說“fellow”時,系統可以針對對應的四個音素(/f/,/ɛ/,/l/,/o/)給出從0到100的分數。基於這些分數,可以再對兩個音節(/fɛ/和/lo/)進行評分。同樣地,也可以對單詞進行評分,然後再對整個句子進行評分,得到各層次的分數。在發音不完美的情況下,它能夠匹配最相似的發音,例如“你的/ɛ/聽起來像/a/”。
一些進階的語音評分系統還包含了口說能力評量模型,可以就發音準確度、流暢性和完整度等面向給予語句層級的整體評分,幫助學習者更提升語言的自然度和流暢度;另外也包
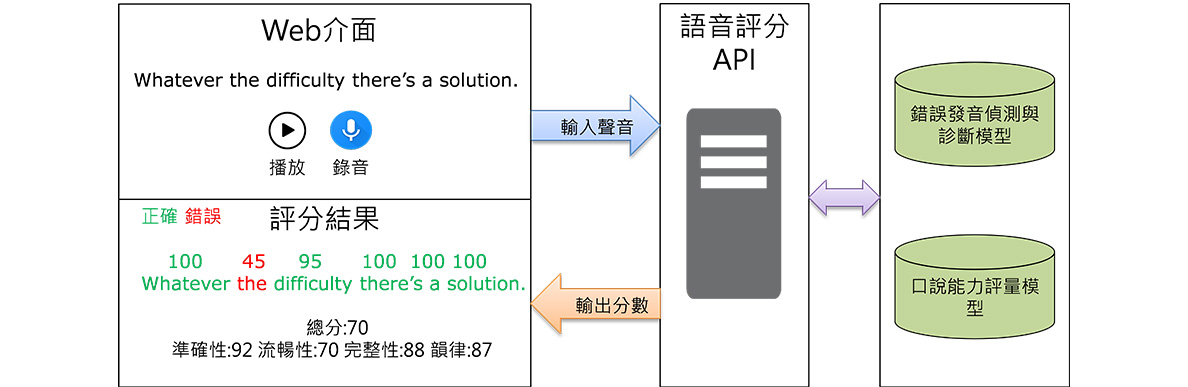
含了句子節奏、重音、聲調等辨識模型,讓學習者更好地掌握語言的韻律特徵,如英語的上升和下降音調。圖1為英語語音評分系統示意圖,包含前端使用者介面與後端評分API,使用者透過前端錄音將聲音送至後端API進行評分,評分完成後分數結果回傳呈現在使用者介面上,後端也包含錯誤發音偵測與診斷及口說能力評量等兩種評分模型。
二、 語音評分的應用
語音評分在語言教育中的應用,主要是幫助學生練習外語發音和口語表達。學生可以透過手機應用程式或網路平台進行練習,後端平台接收到學生發音後,透過評分模型評估發音正確性,再給予即時的反饋及建議;透過這種模式,可讓學生在家中、公共場所或旅行中隨時隨地練習並修正口語表達,而不必等到下一次去教室上課。語音評分技術在語言學習中已經有多個實際應用案例,下面列出幾個案例:
Duolingo是一個知名的語言學習應用程式,全球下載量超過5億次,它使用語音評分技術來幫助用戶練習發音。用戶可以通過對著麥克風朗讀句子,系統會自動評估其發音的準確性。該功能能夠提供及時的反饋,幫助學習者改善發音技巧。
ELSA Speak是一個語音發音和口說流利度訓練應用程式。它根據每個使用者的語音特徵和學習需求,提供定制化的練習內容和建議,還提供了各種主題的對話練習和角色扮演,讓學習者在實際情境中練習英語對話,從而提升溝通能力,已經成為許多人在學習英語口說方面的首選工具之一。
美國教育考試服務中心(ETS)的SpeechRater是一個英語語音評分系統。它能夠自動評估口說回答的流暢度、發音準確性和語法使用等方面。該系統已被用於英語考試中,如TOEFL(托福)口說評分,這種基於語音評分的測驗不僅可以提高考試的準確性和客觀性,還可以減輕考試官的工作負擔。
這些案例展示了語音評分技術在語言學習中的實際應用。透過這些技術,學習者能夠獲得準確的發音評估和及時的反饋,從而提高他們的口說表達能力。這些應用案例同時也反映了語音評分技術在語言教育中的重要性和效益。
三、 語音評分於語言學習的挑戰
語音評分在語言學習中仍然面臨挑戰。首先,不同人的說話方式、口音和語音特徵存在差異,這會對模型的準確性產生影響。其次,語音評分對環境噪音和干擾等因素比較敏感,這些因素可能會對學習者發音評估造成一定的影響。最後,學生通常需要在幾秒鐘內接收到反饋,否則無法及時反映學習效果將使學習者失去耐心,因此對網路或電腦的計算資源要求將較高。
解決方案之一是進行語音數據的多樣化訓練,包括來自不同說話者和不同口音的語料。將可使模型更具強健性,能夠更好識別和適應不同的語音特徵,也可以利用預訓練模型並進行微調來緩解訓練語料不足的情況。另外是對語音數據進行降噪處理,以減少背景噪音的干擾,或使用麥克風陣列等高品質的音頻設備,能夠提供更清晰的語音信號,從而提升辨識的準確性。回應時間的效能問題,則可使用低延遲的非自迴歸式(一般需逐字辨識,非自迴歸式可同時辨識整句)端到端模型[3]等新式模型改善,以及隨著高速網路時代普及,將可逐漸彌平此問題。
此外,也需要考慮到倫理和隱私問題。例如,學生語音資料可能會被收集儲存,需要有嚴格的隱私保護措施。評分標準和方法也需要公正和透明,以避免對學生造成不當影響。
參 結論
回顧本文所介紹的AI語音評分在語言教育的應用,可以看出這項技術已經在語言學習領域中占據了重要地位,為語言學習者提供更有效、更便利的學習方式。但也需要注意應用過程中面臨的挑戰和限制,而且需要充分考慮隱私和安全問題。
為了進一步提升語音評分在語言教育的應用效果,需要持續優化語音評分演算法和改良模型架構,加強語言學習教材和教學方法開發,最終提高實際應用中的準確性和穩定性。同時,也需要對語言教育市場調查分析,深入了解用戶需求與潛在市場,進一步完善語言教育產品和服務,提高語言教育產業的發展水平和競爭力。
作為一所致力於創新技術的研發機構,本院將繼續關注語音評分在語言學習的應用,加強與科技企業和研究機構合作,推進語言教育產業創新發展,為客戶提供更優質、更有效的語言學習體驗。
肆 參考文獻
[1] S. M Witt and S. J Young, “Phone-level pronunciation scoring and assessment for interactive language learning,” Speech Communication, vol. 30, pp. 95–108, 2000.
[2] T.-H. Lo et al., “An effective end-to-end modeling approach for mispronunciation detection,” in Proc. of the Annual Conference of the International Speech Communication Association (Interspeech), 2020.
[3] Y. Higuchi et al., “Mask CTC: Non-autoregressive end-to-end ASR with CTC and mask predict,” in Proc. of the Annual Conference of the International Speech Communication Association (Interspeech), 2020.