壹 前言
隨著大型語言模型(Large Language Models, LLMs)在自然語言處理領域的突破性進展,其在生成式任務中的應用日益廣泛,檢索增強生成(Retrieval-Augmented Generation, RAG)技術應運而生,透過專有知識庫輔助生成過程,提升準確性與可解釋性。舊有RAG主要依賴於向量檢索與語義相似度,面臨了這三項挑戰:資訊孤島(文本區塊之間缺乏明確連接,難以捕捉深層關係)、上下文不足(對複雜問題提供的上下文有限),以及幻覺問題(LLM可能生成看似合理但實際不準確的內容)。
Graph RAG技術結合知識圖譜(Knowledge Graph, KG)與 RAG 架構,知識圖譜是一種以圖形結構儲存和組織的結構化知識庫,將現實世界中的實體(人、事、地、物、概念等)及其之間的關聯連結起來,形成網狀的知識網絡。它透過「實體-關係-實體」三元組的方式呈現知識,提供更結構化、可追溯且具推理能力的知識支援,來解決舊有RAG這三個問題,目前Graph RAG的介紹與發展可先參考[1]。
貳 Graph RAG 技術架構與實作
一、 Graph RAG技術架構
Graph RAG的技術架構包含了三個關鍵技術:從知識文件中擷取實體(Entities)和關係(Relationships)、建立知識圖譜以及提取知識的檢索(Retrieval)策略,要實作一個實際Graph RAG的應用,這三個關鍵技術缺一不可,分別說明如下:
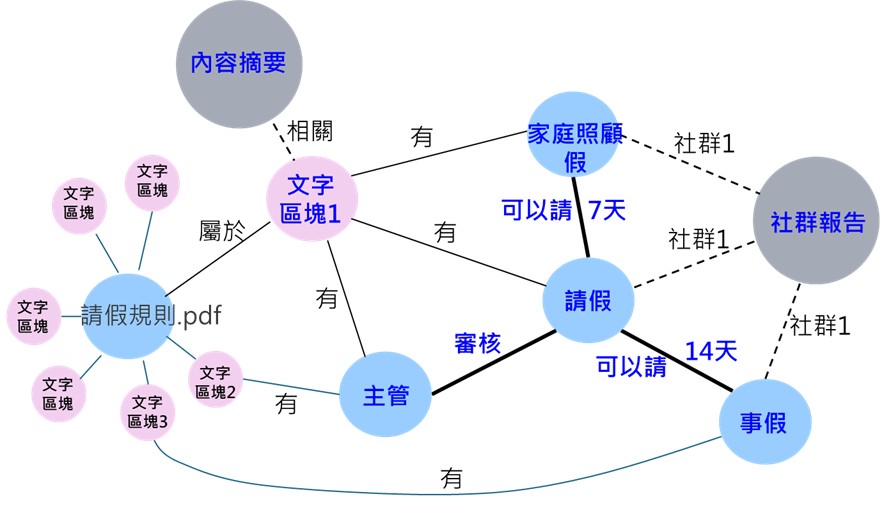
(一) 從知識文件中擷取實體和關係 從非結構化文本中切割成文字區塊(Text Chunks)並自動提取實體與關係,以及生成高階實體與摘要,使用各公司都有的請假規則範例來說明此一實作流程(圖1):
(1) 知識文件檔案「請假規則.pdf」為某一公司的請假規則,內容包含了所有可以請的假別,例如特休假、事假、家庭照顧假等,也包含了可請天數、請假應附的佐證資料、該如何填寫假單及核假的程序。
(2) 「請假規則.pdf」會先轉成文字檔然後進行切塊,切塊會將文字檔切分成若干個文字區塊,文字區塊個數會隨區塊大小(Chunk Size)及重疊區域大小(Overlap Size)設定而不同,假設在這個案例中會被切分成7個文字區塊。
(3) 接著在每個文字區塊中萃取出實體,例如:從文字區塊1萃取出「家庭照顧假」、「請假」、「主管」等3個實體,在文字區塊2中同樣取出「主管」實體,另外從文字區塊3中萃取出「事假」實體,以此類推到其他的文字區塊。
(4) 從文字區塊中除了擷取出實體外,同時也要萃取出實體與實體間的關係,例如:「家庭照顧假-請7天/年-請假」、「事假-請14天/年-請假」、「主管-審核-請假」等3個關係。
(5) 萃取出基本的實體與關係後,需要再找到關聯性強的實體與關係建立高階的「社群」實體,或將文字區塊文字內容生成「內容摘要」實體(摘要或相關的問題組),並建立與其他實體間的關係。
(二) 建立知識圖譜
彙整所有實體與所有關係,包含生成的與萃取出來的,形成一個圖結構的知識圖譜並存入可儲存圖結構的資料庫中,如圖1。
(三) 提取知識的檢索策略
對於複雜問題需要能根據問題從知識圖譜提取足夠且正確的上下文(Context)知識,才能讓LLM生成正確的答案,這部分的實作方法涉及圖搜尋演算法,對回答正確率影響很大。
基於開發者社群和生態系統的大小、目前關注度較高、有提供上述三個關鍵技術等三項因素的考量,選出「微軟GraphRAG專案」與「LangChain與Neo4j整合實作」兩項來說明Graph RAG實作技術,並於表1中做簡單比較。
二、 微軟 GraphRAG 專案
微軟的GraphRAG開源專案[2],目前已釋出v2.6.0版,具備以下核心特點:
(一) 知識圖譜建構
GraphRAG開源專案能自動從非結構化文本中提取實體與關係:
(1) 實體可以是人、地點、事件、概念等,自動從知識文件中判斷不同知識領域(Domain)的實體定義。
(2) 通常還會包括文本單元(TextUnit),為待分析的文本塊,以及共變數 (Covariate),是關於實體的聲明資訊。
(3) 建構好的知識圖譜以Parquet檔案格式儲存。
(4) 對知識圖譜執行社群檢測算法(Leiden 算法),將知識圖譜分割成多個社群(Communities),並為每個社群生成一個社群摘要(Community Report),捕捉該社群的核心資訊。
(二) 檢索策略
透過「本地到全局(Local to Global)」架構,整合文件內部資訊與圖譜中實體關係[3],提供多元檢索策略包括基於向量檢索的Basic Search、基於圖譜結構的Local Search與Global Search,以及地毯式全面檢索的Drift Search等,靈活應對不同問答需求。
(三) 擴展彈性
採API 模組化設計,提供從資料擷取、圖譜構建到生成的完整 API,便於開發者整合與部署,但不容易擴充不同的或客製化的檢索策略。
實際應用挑戰:
(一) 高建置與維運成本:知識圖譜建構需高品質資料與複雜處理流程,加上大量的LLM呼叫,且更新需重新索引,需要較高的系統建置及運作成本。
(二) 效能瓶頸:大規模圖譜檢索可能導致查詢延遲,特別是在全面檢索場景中。
三、 LangChain 與 Neo4j 整合實作
LangChain 與Neo4j圖形資料庫的整合提供了高度彈性與擴展性,實作方法如下:
(一) 知識圖譜建構
LangChain提供了LLMGraphTransformer 模組以及高度整合的Neo4j模組,可將知識文件從文本轉換成實體和關係的圖結構資料,再將此知識圖譜載入儲存在Neo4j圖形資料庫中。
(二) 檢索策略
Neo4j本身的圖查詢語法(Cypher)與圖演算法,可以在LangChain 框架中操作Neo4j與向量查詢的混合檢索,提升查詢精度。除此之外,亦可進一步擴展實作進階圖譜檢索方法[5],以原有的文本區塊為父區塊,生成下列三種子區塊,形成父子關係並加入索引,檢索子區塊提取的知識會包含父區塊的上下文,兼顧資訊密度與檢索效率:
(1) Parent Retriever:將文本區塊再分成更小的區塊作為子區塊。
(2) Hypothetical Questions:為文本區塊生成潛在問題集作為子區塊。
(3) Summaries:摘要文本區塊作為子區塊。
(三) 擴展彈性
在擴展強化知識圖譜的推理能力方面,Step-Back Prompting[4]是一種引導 LLM 進行抽象化推理的提示技術,執行推理步驟來遍歷(Traversal)知識圖譜以尋找實體之間的間接關係,並綜合資訊得出最終答案,方法如下:
(1) 抽象化推理流程:Step-Back Prompting引導大型語言模型透過模型抽象化,跳脫細節限制,聚焦於核心概念,再基於此進行推理,進而提升推理的準確性與效率。
(2) 生成Step-Back Question:從原始問題中衍生出一個更高層次的、更抽象的問題,例如,針對「某人在某年就讀哪所學校」的問題,先抽象為「其教育歷史」。
(3) 簡化推理路徑:透過抽象問題引導模型聚焦於核心知識,提升推理準確性。
實際應用挑戰:
(一) 自動化程度不足:雖然彈性很高,但皆需自行開發程式模組、提示設計(Prompt)與進階檢索功能以實現完整知識圖譜RAG,缺乏微軟GraphRAG的高度自動化。
(二) 高度依賴提示工程:需要有好的檢索方法與提示設計才能得到好的答案品質與效能。
表1為這兩項Graph RAG實作技術的比較,應根據組織規模、資料複雜度與人力資源作綜合考量:
| 項目 | 微軟 GraphRAG 專案 | LangChain 與 Neo4j 整合實作 |
| 客製化開發 | 客製化整合困難度高。 | 提供框架,客製化開發彈性高。 |
| 中LLM 模型 | 主要支援Azure gpt-4系列 LLM 模型 | LLM 模型調用可自選(如 gpt-4、開源模型),可依據需求調整成本 |
| 檢索效率 | 查詢效率較穩定。 Global/Local Search查詢支援串流式回傳,動態社群剪枝可有效降低查詢負擔 |
依賴Neo4j的圖查詢效率。 大型圖譜需優化Cypher降低查詢延遲,結合向量查詢可提升檢索效率 |
| 技術優勢 | 自動化程度高、查詢穩定性、多跳推理與全局語境處理上具優勢,適合複雜問題 | 可結合多種RAG技術、靈活度高,適合需細緻控制查詢邏輯的場景及搭配客製化設計的推理機制 |
| 技術劣勢 | 圖譜建構與查詢均需多次呼叫LLM,模型成本較高 | 開發建置需熟悉 Neo4j、Cypher、LangChain與提示工程,專業門檻高 |
四、 Graph RAG與RAG適用性比較
Graph RAG透過實體與實體以及實體與文本區塊的關係,取得與問題有高度關聯且彼此相關的上下文知識,解決了RAG在資訊孤島、上下文不足以及幻覺的問題,但仍無法適用於全部問題,2025年一篇研究[6]提出了兩種RAG的適用情境評估,以文字任務(如問答與摘要)比較兩者的優劣勢與互補性,根據其試驗結果,得到兩項技術比較及其適用情境如表2。文中並提到了兩種RAG與GraphRAG混合使用策略及其優缺點:
(一) 選擇式(Selection):根據問題的特性,動態選擇使用 RAG 或 GraphRAG 來處理每一個問題。優點:效率高、成本低;缺點:效能受限於分類器準確度、無法同時利用兩種技術的優勢。
(二) 整合式(Integration):對每個問題同時使用 RAG 與 GraphRAG 進行檢索,將兩者的結果合併後再進行生成。優點:效能最佳、適合複雜查詢與多跳推理任務;缺點:成本高(執行兩次檢索與生成)、效率低,但適合高精密度任務。
| 項目 | RAG | Graph RAG |
| 資料類型 | 非結構化文字資料 | 結構化資料或可轉換為圖的文字資料 |
| 查詢類型 | 單跳問題、細節導向問題 | 多跳推理問題、跨段落/跨文件問題 |
| 摘要任務 | 擅長捕捉細節、精準回答 | 擅長生成多面向、具多樣性的摘要 |
| 檢索方式 | 向量相似度、語義搜尋 | 圖結構搜尋、社群摘要、實體關係推理 |
| 優勢 | 快速、準確、易於部署 | 推理能力強、可處理複雜關聯 |
| 劣勢 | 缺乏推理能力、容易幻覺 | 建構成本高、圖譜品質影響大 |
| 適用任務 | FAQ、事實查詢、精準摘要 | 知識密集任務、跨文件整合 |
| 適合使用情境 | •查詢內容明確、可直接從文本擷取答案 •資料量大但結構鬆散,無需建立知識圖譜 •需要快速部署與低建置成本的應用場景 •單一文件或短文本摘要任務 |
•查詢需跨段落、跨文件推理,或需多步邏輯推導 •資料具結構性或可轉換為圖結構(如政策規範、醫療紀錄) •需要高可解釋性與知識追溯能力 •多代理系統或需共享知識庫的應用架構 |
參 未來挑戰與發展方向
一、 系統整合與多代理(Multi-Agent)協同
Graph RAG利用知識圖譜技術仍需要在多個步驟推理的任務中確保低錯誤率,因為在多次檢索和生成過程中可能累積錯誤。在多代理架構中,結合知識圖譜作為共享知識庫,實現多個代理間的協同推理與策略規劃均使用一致且正確的知識,提升系統整體智慧。例如,在一個多代理系統中有一個專門負責檢索的代理,利用知識圖譜和多種檢索技術找到所需的知識,另一代理則利用知識圖譜更好地理解領域知識,從而更精確地處理特定領域的複雜應用,微軟的Agentic-GraphRAG可為代表。
二、 特定領域應用支援
Graph RAG 尤其適合處理結構複雜、知識密集的領域應用,在業界的案例有:SAP 的 AI Agent Joule 結合 Graph RAG 技術,能理解並處理複雜的企業業務問題,展現其在垂直領域的應用潛力; ArangoDB在醫療領域方面的Graph RAG技術改變了舊有醫療保健資料管理方法,整合病患資料、診斷紀錄、治療方案與研究文獻,建立「病患全貌視圖」,提供一個個人化醫療的解決方案。
三、 知識圖譜更新效率優化
目前的知識圖譜建構流程多依賴靜態文檔,過程繁瑣且耗時。每次更新資料時,需重複整個流程,難以應對即時業務需求與決策挑戰,要如何讀取動態的資訊,改善異動知識圖譜的機制增進更新效率,還要能維持要求的準確性便成為關鍵。
四、 多模態知識圖譜發展融合
人類感知本質即為多模態,因為我們周圍的物體通常由多種訊號(例如視覺和文字)的組合表示,未來Graph RAG應朝向整合圖像、語音等多模態訊號的知識圖譜(Multi-Modal Knowledge Graph, MMKG)發展[7],進一步拓展其應用邊界。
肆 結論
Graph RAG 技術透過結構化知識與語意推論,能大幅提升大型語言模型的回答品質與解釋能力。儘管其建置與維運成本高於傳統 RAG,但在處理複雜查詢與知識密集任務上展現出強大潛力,隨著工具與框架的成熟,Graph RAG 有望成為企業與研究機構在智慧應用領域的重要技術選項。
伍 參考文獻
[1]. 劉佳苹(資策會), "Graph RAG-RAG結合知識圖譜之技術解析及應用," https://www.moea.gov.tw/mns/doit/industrytech/IndustryTech.aspx?menu_id=13545&it_id=563
[2]. Microsoft GraphRAG project, https://github.com/microsoft/graphrag
[3]. Darren Edge et al., "From Local to Global: A Graph RAG Approach to Query-Focused Summarization," https://arxiv.org/abs/2404.16130
[4]. Huaixiu Steven Zheng et al., "Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models," https://arxiv.org/abs/2310.06117
[5]. Tomaž Bratanič, " Implementing Advanced Retrieval RAG Strategies With Neo4j," https://neo4j.com/blog/developer/advanced-rag-strategies-neo4j/
[6]. Haoyu Han et al., "RAG vs. GraphRAG: A Systematic Evaluation and Key Insights," https://arxiv.org/pdf/2502.11371
[7]. Wanying Liang et al., "A Survey of Multi-modal Knowledge Graphs: Technologies and Trends," in ACM Computing Surveys Vol. 56, No. 11, https://dl.acm.org/doi/10.1145/3656579