

Image Understanding And Multimedia Content Generation
概述
隨著人工智慧技術的日益成熟,視覺感知相關技術已有了關鍵性突破,進一步擴展至影像認知理解與多媒體內容生成之智慧化整合發展新階段。本院在人工智慧影像領域的重要研發方向,聚焦以人為核心的人臉辨識與行為辨識技術研究,透過精準識別個人身份與特徵,深化對行為意涵之理解,廣泛應用於智慧導覽、安全監控、人員管理及科技執法等領場域;同時,亦致力於多媒體內容生成技術與應用研發,實現圖像、影片、動畫及音樂音效等多元生成成果,賦能與影音創意內容製作,實現智慧城市的發展願景,開啟未來數位生活之嶄新篇章。Image Understanding And Multimedia Content Generation
核心技術
- 人臉辨識
- 人形與行為辨識
- 擬真人生成
- 多媒體內容生成
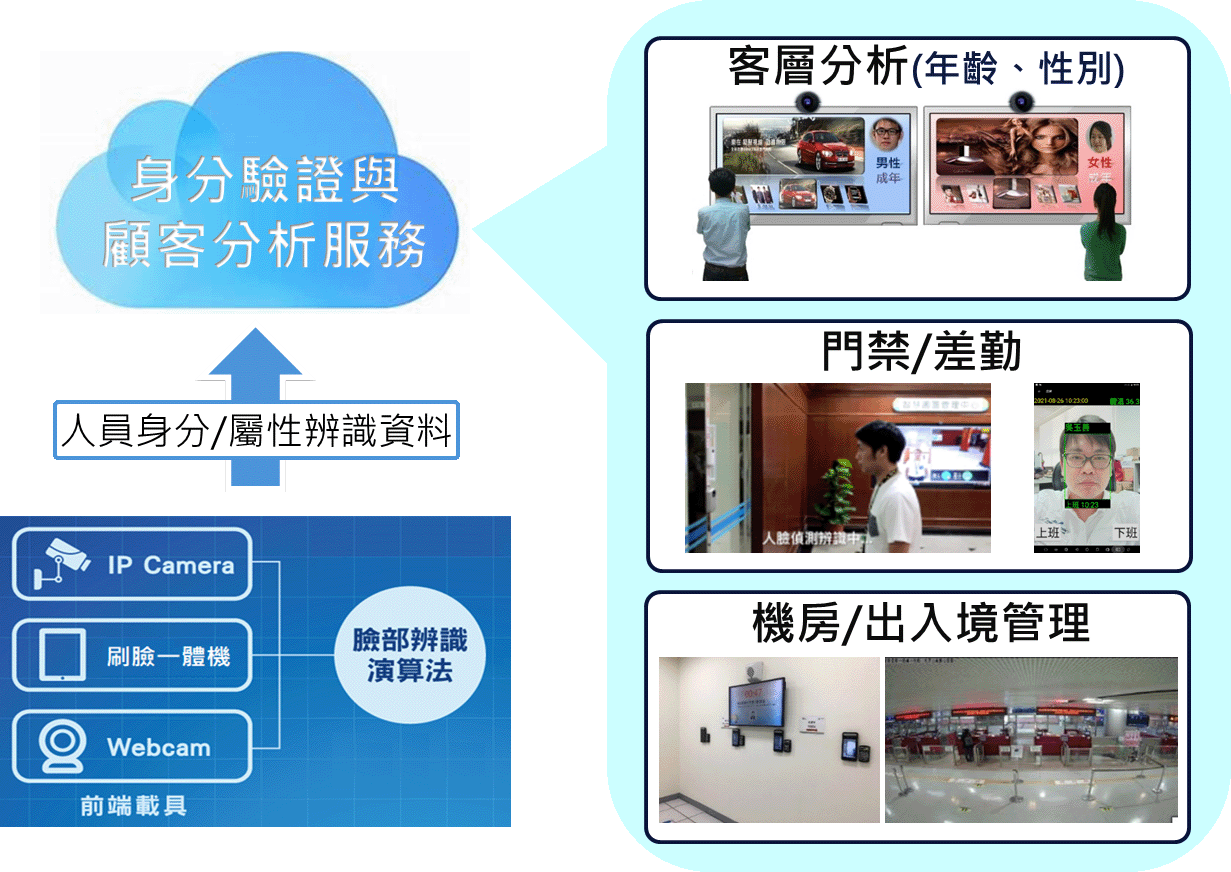
人臉辨識與應用示意圖
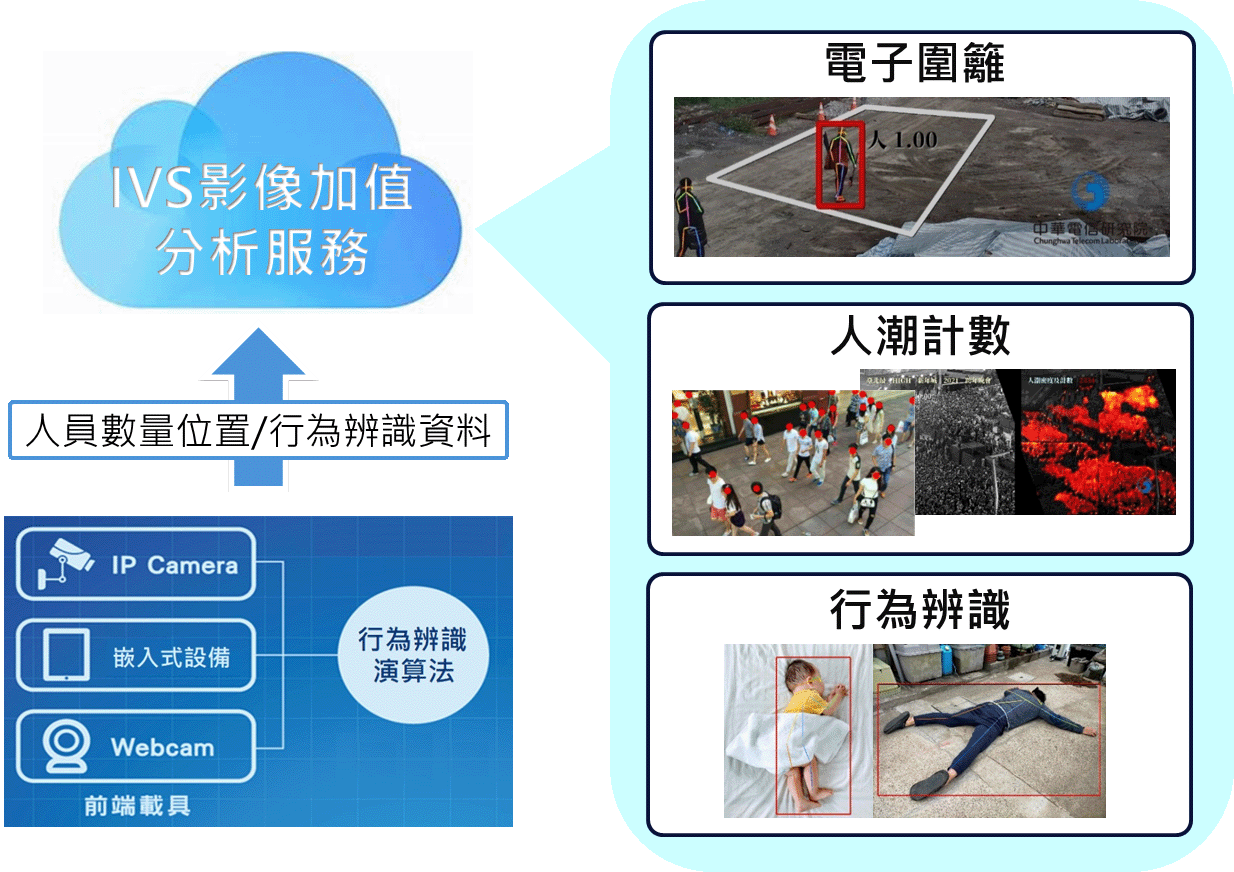
人形/行為辨識與應用示意圖
擬真人生成與應用示意圖

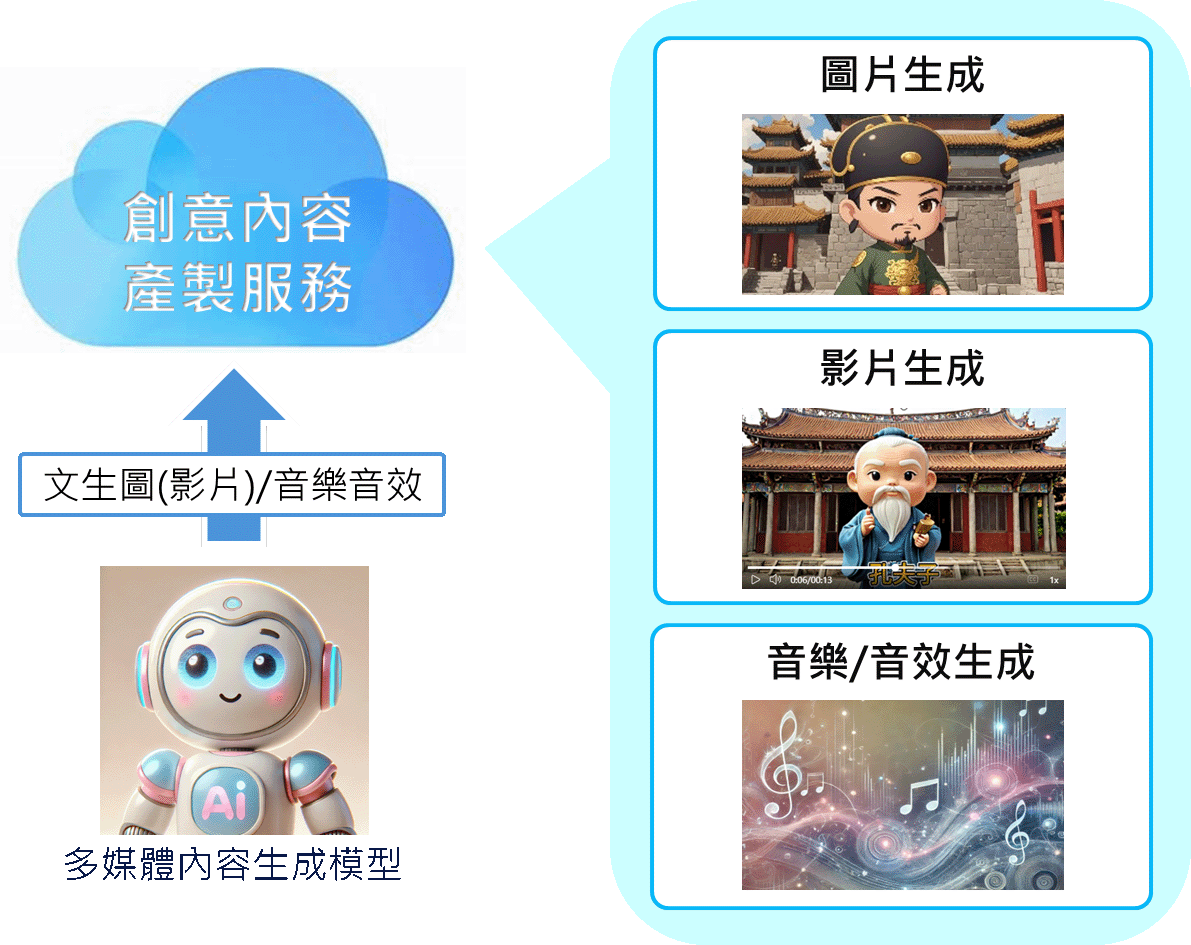
多媒體內容生成示意圖
Image Understanding And Multimedia Content Generation
應用現況
人臉辨識:透過人臉辨識技術,做到識別人員身分、瞭解人員屬性(性別/年齡層/臉上特徵),甚至防疫期間口罩是否配戴等辨識,本院技術達國內領先群並具備商用水準。人臉辨識技術成果亦積極參與且取得國際評比的肯定(美國NIST FRTE 1:1 2025/12月台灣排名第1名;人臉活體辨識通過美國iBeta實驗室 Level 1 認證),陸續成功應用於中小企業門禁管控、電子看板來客分析、國境大門身分確認、門市零接觸取號碼單、政府機關高機敏場所管控等。近年來Edge AI需求盛行,亦將人臉辨識輕量化佈署於嵌入式攝影機/一體機裝置上,擴展人臉辨識產品。
人形與行為辨識:以AI深度學習影像技術可識別出眾多人形與行為資訊,例如:人員外形、人員所在空間位置、計算特定區域人潮數量、檢索人員衣著/顏色、瞭解單人甚至多人的互動行為等。本院將技術成果導入既有的電子圍籬方案,大幅改善傳統電子圍籬容易誤偵測問題,提供即時告警加值服務,並應用於國家關鍵基礎設施、台鐵邊坡工程、重要機房、風景區等監控需求上。此外,人形辨識技術將往嵌入式邊緣運算方向發展,打造出低成本/低耗電/更快速的新一代IVS解決方案。
擬真人生成:可與語音辨識、知識問答、語音仿聲、文生圖技術融合生成即時互動擬真人,具備自然手勢動作互動、中文口型精準匹配特點,還能根據音檔長短選用合適的手勢;打造一個推廣知識/產品的擬真人解決方案,針對機構/個人建立專屬知識庫,並塑造專屬的形象人物,以問答方式進行資訊傳遞及行銷傳播。
多媒體內容生成:建構在SOTA AI模型架構上,研發包含圖像、影片、動畫及音樂音效等多元的內容生成成果,透過在地化資料進行模型精進與訓練,強化台灣在地化元素且具備高品質創作表現。於多媒體影像與影片理解技術上,專注發展多模態語言模型,搭配鑑別式AI與Edge AI等提供人形辨識之創新應用。研發成果應用於智慧安防監控及創意內容產製等領域,展現在地化技術實力。